2026-04-20 TIL (40일차)
알고리즘
- 참고 강의: 알고리즘 강의
정렬 알고리즘
정렬이란 데이터를 특정한 기준에 따라 순서대로 나열하는 것을 말합니다. 일반적인 문제 상황에 따라서 적절한 정렬 알고리즘이 공식처럼 사용됩니다.
• 선택 정렬
처리되지 않은 데이터 중에서 가장 작은 데이터를 선택해 맨 앞에 있는 데이터와 바꾸는 것을 반복합니다.
시간 복잡도
- 선택 정렬은 N번 만큼 가장 작은 수를 찾아서 맨 앞으로 보내야 합니다.
- 구현 방식에 따라서 사소한 오차는 있을 수 있지만, 전체 연산 횟수는 다음과 같습니다. \(N + (N - 1) + (N - 2) + ... + 2\)
- 이는 $(N^2 + N - 2) / 2$ 로 표현할 수 있는데, 빅오 표기법에 따라서 $O(N^2)$이라고 작성합니다.
• 버블 정렬
서로 인접한 두 원소를 검사하여 정렬 기준에 맞지 않으면 자리를 교환(Swap)하는 알고리즘입니다. 큰 값이 마치 거품(Bubble)처럼 배열의 끝으로 밀려 올라가는 모습에서 유래되었습니다.
- 작동 원리 (오름차순 기준)
- 배열의 첫 번째 원소와 두 번째 원소를 비교합니다.
- 앞의 원소가 더 크면 두 원소의 자리를 바꿉니다.
- 이 과정을 배열의 끝까지 반복하면, 가장 큰 값이 맨 끝으로 이동하게 됩니다.
- 맨 끝 위치를 제외하고, 다시 처음부터 이 과정을 반복합니다.
시간 복잡도
- 최선 (Best): $O(N)$ (이미 모두 정렬되어 있고, 최적화 플래그를 사용한 경우)
- 평균 (Average): $O(N^2)$
- 최악 (Worst): $O(N^2)$ (역순으로 정렬되어 있을 때)
- 공간 복잡도: $O(1)$ (주어진 배열 안에서만 자리를 바꾸므로 추가 메모리 불필요)
• 삽입 정렬
처리되지 않은 데이터를 하나씩 골라 적절한 위치에 삽입합니다. 선택 정렬에 비해 구현 난이도가 높은 편이지만, 일반적으로 효율적으로 동작합니다.
- 첫번째 데이터는 그 자체가 정렬되어있다고 판단하고 두번째 데이터부터 어떤 위치(왼쪽,오른쪽)으로 들어갈지 판단하는 로직입니다.
시간 복잡도
- 삽입 정렬의 시간 복잡도는 $O(N^2)$이며, 선택 정렬과 마찬가지로 반복문이 두 번 중첩되어 사용됩니다.
- 삽입 정렬은 현재 리스트의 데이터가 거의 정렬되어 있는 상태라면 매우 빠르게 동작합니다.
- 최선의 경우 $O(N)$의 시간 복잡도를 가집니다.(이미 정렬되어 있는 상태)
- 이유: 삽입 정렬은 자신의 자리를 찾을 때 ‘왼쪽 원소들’과 차례대로 비교합니다. 만약 배열이 이미 오름차순으로 완벽히 정렬되어 있다면, 타겟이 되는 원소는 자신의 바로 왼쪽 원소와 1번만 비교해 보고 “내가 더 크니까 제자리에 가만히 있으면 되겠구나” 하고 내부 반복문(탐색)을 즉시 종료합니다(
Break). - 즉, $N$개의 원소가 각각 단 1번의 비교만 수행하므로 전체 연산 횟수가 $N$번으로 최적화되어 $O(N)$의 빠른 속도를 냅니다.
• 병합 정렬
존 폰 노이만이 고안한 알고리즘으로, 분할 정복(Divide and Conquer) 방식의 꽃입니다. 배열을 가장 작은 단위(크기 1)가 될 때까지 반으로 계속 쪼갠 뒤, 다시 크기 순서대로 정렬하면서 합치는(Merge) 알고리즘입니다.
- 작동 원리 3단계 (Divide - Conquer - Merge)
분할 (Divide)
입력 배열을 같은 크기의 2개의 부분 배열로 재귀적으로 계속 반으로 나눕니다. (더 이상 나눌 수 없는 크기 1이 될 때까지 진행합니다.)정복 (Conquer)
부분 배열의 크기가 1이 되면, 원소가 하나뿐이므로 그 자체로 이미 정렬된 상태라고 봅니다. 이제 나뉜 부분 배열들을 2개씩 짝지어 다시 합치기 시작합니다.병합 (Merge)의 상세 프로세스
병합 과정은 ‘이미 키 순서대로 서 있는 두 줄(배열)을, 하나의 정렬된 긴 줄로 합치는 과정’과 같습니다. 두 배열을 맨 앞에서부터 가리키는 투 포인터(Two Pointers) 방식을 사용합니다.
[예시]
왼쪽 줄(배열 A)과오른쪽 줄(배열 B)이 있고, 각각 이미 오름차순(키 작은 순)으로 정렬되어 서 있습니다.
- 맨 앞 사람끼리 비교: * 왼쪽 줄의 맨 앞 사람(포인터
i)과 오른쪽 줄의 맨 앞 사람(포인터j)의 키를 비교합니다. - 작은 사람 이동: * 키가 더 작은 학생을 뽑아 새로운 임시 줄(결과 배열 Temp)의 맨 뒤(포인터
k)에 세웁니다. - 포인터 이동: * 방금 학생이 뽑혀나간 줄은 그다음 사람이 맨 앞으로 나오게(포인터 +1) 합니다.
- 반대쪽 줄은 아직 뽑히지 않았으므로 그대로 대기합니다.
- 반복: * 위 1~3번의 과정을 어느 한쪽 줄이 텅 빌 때까지 계속 반복합니다.
- 나머지 털어넣기 (잔여물 처리): * 한쪽 줄이 다 비워지면, 반대쪽 줄에는 아직 사람들이 남아있게 됩니다.
- 남은 사람들은 이미 자기들끼리 키 순서대로 정렬되어 있으므로, 비교할 필요 없이 그대로 새로운 줄(Temp) 뒤에 순서대로 이어 붙여줍니다.
시간 및 공간 복잡도
- 시간 복잡도: $O(N \log N)$ (최선, 평균, 최악 모두 동일. 어떤 데이터가 들어와도 항상 일정한 성능을 보장!)
- 공간 복잡도: $O(N)$ (병합 결과를 담아둘 임시 배열(Temp Array)을 위한 추가 메모리가 반드시 필요함)
• 퀵 정렬
- 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법입니다.
- 일반적인 상황에서 가장 많이 사용되는 정렬 알고리즘 중 하나입니다.
- 병합 정렬과 더불어 대부분의 프로그래밍 언어의 정렬 라이브러리의 근간이 되는 알고리즘입니다.
- 가장 기본적인 퀵 정렬은 첫 번째 데이터를 기준 데이터(Pivot)로 설정합니다.
Tip: 퀵 정렬은 내부적으로 재귀 함수(Recursive Function)를 활용하여 구현됩니다.
[동작 과정]
- 피벗 설정: 배열의 첫 번째 원소를 피벗(기준값)으로 설정합니다.
- 탐색 시작:
- 왼쪽에서 오른쪽으로: 피벗보다 큰 데이터를 찾을 때까지 이동합니다.
- 오른쪽에서 왼쪽으로: 피벗보다 작은 데이터를 찾을 때까지 이동합니다.
- 교환 (Swap): * 찾은 두 원소의 위치를 서로 바꿉니다.
- 이 과정을 두 탐색 위치가 서로 엇갈릴 때까지 반복합니다.
- 분할 (Partition/엇갈림 발생): * 왼쪽 탐색 위치와 오른쪽 탐색 위치가 서로 엇갈리게 되면(왼쪽 인덱스 > 오른쪽 인덱스), 피벗과 엇갈린 두 원소 중 더 작은 값(오른쪽 탐색 위치의 값)의 위치를 교환합니다.
- 재귀적 수행:
- 이제 피벗은 배열의 중간쯤 위치하게 되며, 피벗을 기준으로 왼쪽 묶음은 모두 피벗보다 작고, 오른쪽 묶음은 모두 피벗보다 큰 상태가 됩니다. (이를 분할이라고 합니다.)
- 나누어진 왼쪽 묶음과 오른쪽 묶음에 대해 위 과정을 각각 독립적으로 다시 수행(재귀 호출)하여 전체 배열을 정렬합니다.
시간 복잡도
- 이상적인 경우 분할이 절반씩 일어난다면 전체 연산 횟수로 $O(N \log N)$을 기대할 수 있습니다.
- 너비 X 높이 = $N \times \log N = N \log N$
- 퀵 정렬은 평균의 경우 $O(N \log N)$의 시간 복잡도를 가집니다.
- 하지만 최악의 경우 $O(N^2)$의 시간 복잡도를 가집니다.
- 이유: 가장 기본적인 퀵 정렬은 ‘첫 번째 원소’를 피벗으로 삼습니다. 만약 데이터가 이미 오름차순(또는 내림차순)으로 정렬되어 있는 상태라면, 첫 번째 원소는 항상 배열 내의 ‘최솟값(또는 최댓값)’이 됩니다.
- 이 최솟값을 기준으로 분할을 시도하면, 피벗보다 작은 왼쪽 묶음은 0개, 피벗보다 큰 오른쪽 묶음은 $N-1$개로 극단적으로 치우친 분할이 일어납니다. 절반씩 쪼개지는 $\log N$ 깊이의 트리가 아니라, 매번 데이터가 1개씩만 줄어드는 깊이 $N$짜리 일자형 트리가 되어버립니다.
- 따라서 탐색 연산이 $N + (N-1) + (N-2) + … + 1$ 번 일어나게 되어 결국 $O(N^2)$의 속도 저하가 발생합니다.
• 계수 정렬
- 특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠르게 동작하는 정렬 알고리즘입니다.
- 계수 정렬은 데이터의 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때 사용 가능합니다.
- 데이터의 개수가 $N$, 데이터(양수) 중 최댓값이 $K$일 때 최악의 경우에도 수행 시간 $O(N + K)$를 보장합니다.
[동작 과정]
- 데이터 범위 파악 및 카운팅 리스트 생성
- 데이터 범위 확인: 정렬할 데이터 중 가장 작은 수와 가장 큰 수의 범위를 확인합니다.
- 리스트 초기화:
[최소값 ~ 최대값]의 모든 숫자를 포함할 수 있는 크기의 빈 리스트(카운팅 배열)를 생성합니다.- 인덱스(Index): 데이터의 값 자체를 의미합니다.
- 값(Value): 해당 데이터가 등장한 횟수(계수)를 저장합니다.
- 데이터 개수 세기 (Counting)
- 데이터를 하나씩 확인하면서, 데이터의 값과 동일한 인덱스의 숫자를 1씩 증가시킵니다.
- 예: 데이터
3을 확인하면 카운팅 리스트의3번 인덱스값을 +1 합니다.
- 정렬된 결과 출력 (Output)
- 카운팅 리스트의 첫 번째 인덱스부터 마지막 인덱스까지 순서대로 확인합니다.
- 리스트에 기록된 계수(갯수)만큼 해당 인덱스 번호를 반복해서 출력합니다.
- 인덱스 자체가 이미 오름차순으로 정렬되어 있기 때문에, 기록된 횟수대로 뽑아내기만 하면 정렬이 완료됩니다.
시간 복잡도
- 계수 정렬의 시간 복잡도와 공간 복잡도는 모두 $O(N + K)$입니다.
- 계수 정렬은 때에 따라서 심각한 비효율성을 초래할 수 있습니다.
- 데이터가 0과 999,999로 단 2개만 존재하는 경우를 생각해 봅시다.
- 계수 정렬은 동일한 값을 가지는 데이터가 여러 개 등장할 때 효과적으로 사용할 수 있습니다.
- 성적의 경우 100점을 맞은 학생이 여러 명일 수 있기 때문에 계수 정렬이 효과적입니다.
• 정렬 알고리즘 비교
| 알고리즘 | 평균 시간 복잡도 | 공간 복잡도 | 핵심 특징 |
|---|---|---|---|
| 선택 정렬 | $O(N^2)$ | $O(N)$ | 아이디어가 매우 간단하고 구현이 쉬움. |
| 삽입 정렬 | $O(N^2)$ | $O(N)$ | 데이터가 거의 정렬되어 있을 때 압도적으로 빠름. |
| 퀵 정렬 | $O(N \log N)$ | $O(N)$ | 대부분의 상황에서 가장 적합하며 충분히 빠름. |
| 계수 정렬 | $O(N+K)$ | $O(N+K)$ | 데이터 크기가 제한된 경우에 한해 매우 빠름. |
코딩 테스트 Tip: 문제에서 특정한 정렬 알고리즘을 직접 구현하라고 요구하지 않는다면, 최악의 경우에도 $O(N \log N)$을 보장하는 언어별 내장 표준 정렬 라이브러리를 사용하는 것이 가장 안전하고 효율적입니다.
TA
1. IK와 FK의 이해
- FK (Forward Kinematics, 순운동학)
- 원리: 부모 관절에서 자식 관절로, 앞에서부터 차례대로 각도를 계산해 나가는 방식입니다. (어깨 👉 팔꿈치 👉 손목)
- 특징: 어깨를 돌리면 팔 전체가 따라 도는 직관적인 방식입니다. 하지만 캐릭터의 손이 ‘정확히 특정 물체를 잡게’ 하거나 ‘발이 땅에 정확히 닿게’ 만드는 등 목표 지점이 있을 때는 계산하기가 매우 까다롭습니다.
- IK (Inverse Kinematics, 역운동학)
- 원리: 자식 관절(끝점, Tip)의 최종 목표 위치(Target)를 미리 정해두고, 그 위치에 도달하기 위해 필요한 중간 관절들의 각도를 수학적으로 역산(Inverse)하여 구하는 방식입니다.
- 특징: 캐릭터의 발이 울퉁불퉁한 계단 높이에 맞춰 자연스럽게 꺾이거나, 문고리에 정확히 손을 가져다 댈 때 사용되는 필수적인 기능입니다.
2. 텍스처와 머티리얼 실전 팁
• AI를 활용한 텍스처 리마스터링
원하는 텍스처를 외부에서 찾기 힘들 때 사용하는 유용한 파이프라인입니다.
- 언리얼 스타터 콘텐츠(Starter Content) 등에서 형태가 마음에 드는 기본 텍스처를 찾아 우클릭 -> Export (
.png)로 추출합니다. - 이 이미지를 AI를 통해 원하는 느낌으로 변경이나 생성 가능합니다.
• Default Lit에서 빛 영향 무시하기
- 머티리얼의 셰이딩 모델이
Default Lit(빛의 영향을 받는 기본 상태)일 때, 텍스처 맵을Base Color와Emissive Color(발광)에 동시에 연결해 보세요. - 효과: 어두운 그림자 속에서도
Emissive값이 색상을 뿜어내어 원래의 텍스처 색상을 선명하게 유지합니다. (반투명 UI나 특수한 카툰 렌더링 요소를 만들 때 유용한 꼼수입니다.)
• 머티리얼 변수 파라미터화
- 단축키
1+ 좌클릭으로Constant노드를 만든 후, 우클릭하여Convert to Parameter로 변경합니다. - 이유: 이렇게 파라미터로 선언해 두면, 굳이 무거운 머티리얼 에디터를 열지 않고도 ‘머티리얼 인스턴스(Material Instance)’ 창에서 스크롤만으로 실시간 값을 조절할 수 있어 작업이 편해집니다.
• World Position Offset (WPO)
- 원리: 픽셀의 색을 칠하는 픽셀 셰이더 단계가 아니라, 그 이전인 버텍스 셰이더(Vertex Shader) 즉, GPU 단계에서 3D 모델의 정점(Vertex) 좌표 자체를 물리적으로 이동시키는 기능입니다.
- 활용: 깃발이 바람에 펄럭이는 모션, 물결이 치는 바다, 캐릭터가 다가갈 때 풀숲이 밀려나는 효과 등을 애니메이션 없이 수학 공식만으로 구현할 수 있습니다.
개념 및 동작 방식
- World Position Offset (WPO)
- 처리 주체: GPU (버텍스 셰이더)
- 이동 방식: 메쉬의 각 버텍스가 개별 이동
- 특징: 바운딩 박스 그대로! (시각적으로만 이동하며, 충돌/컬링 영역은 따라가지 않음)
- Transform (SetActorLocation)
- 처리 주체: CPU (게임 로직)
- 이동 방식: 오브젝트 전체가 통째로 이동
- 특징: 바운딩 박스도 같이 이동 (충돌/컬링 정상 작동)
성능 및 특성 비교
| 항목 | WPO | Transform |
|---|---|---|
| 처리 위치 | GPU (매 프레임, 매 버텍스) | CPU (호출할 때만) |
| 충돌 판정 | 반영 안 됨 | 정상 반영 |
| 컬링(LOD) | 원래 위치 기준 (문제 발생 가능) | 이동 후 위치 기준 (정상) |
| 변형 자유도 | 버텍스별 개별 변형 가능 | 오브젝트 단위 (통째 이동) |
| GPU 비용 | 버텍스 수 × 셰이더 복잡도 | 거의 없음 |
| 대표 사용처 | 풀 흔들림, 물결, 바람 | 캐릭터/오브젝트 이동, 물리 |
| Nanite 지원 | UE 5.4+ 부분 지원 | Nanite와 무관 (정상 작동) |
요약
- WPO = 시각 효과 특화 (GPU)
- Transform = 게임 로직 이동 (CPU)
- 두 기능은 대체 관계가 아니라 역할이 다릅니다.
3. Sine Remapped
- 기본 Sine 노드: 시간이 지남에 따라 파동을 그리며
-1.0 ~ 1.0사이의 값을 무한히 반복합니다. - 문제점: 이 값을 텍스처의 색상이나 모델의 크기에 바로 곱하면,
-1이 되는 순간 크기가 뒤집히거나 색이 검은색으로 깨지는 에러가 발생합니다. 단순히Abs(절댓값)를 씌워 양수로 접어 올리면 파동이 아래로 튕기는(바운스) 형태가 되어 부자연스럽습니다. - Remap의 역할 (
RemapValueRange): * 원본 데이터의 범위(-1.0 ~ 1.0)를 우리가 원하는 안전한 범위(예:0.0 ~ 1.0또는1.0 ~ 1.5)로 비율을 유지한 채 압축/이동(통역)시켜 줍니다.- 자연스럽고 부드러운 호흡, 맥동(Pulse) 애니메이션을 만들 때 핵심적으로 사용됩니다.
4. 노멀 맵의 수학적 원리
3D 그래픽에서 가장 중요하면서도 오해가 많은 부분입니다. 우리는 왜 평평한 폴리곤 화면을 보면서 오돌토돌한 입체감을 느낄까요?
4-1. 입체감과 빛, 그리고 법선 벡터
- 입체감의 비밀: 우리가 굴곡을 느끼는 이유는 오직 “빛의 반사량(명암)” 때문입니다. 빛을 정면으로 받으면 밝고, 굴곡 때문에 빛을 비스듬히 받으면 어두워져 그림자가 집니다.
- 법선 벡터(Normal Vector)의 정의: 표면(Surface)에서 수직으로 90도로 뻗어 나가는 “방향 화살표(벡터)”입니다. 즉, “이 픽셀의 표면이 현재 어느 쪽을 바라보고 있는가?”를 나타냅니다.
- 밝기 계산 (내적, Dot Product): 빛이 들어오는 방향 벡터와 표면의 법선 벡터를 내적(Dot Product) 연산합니다. 두 화살표가 마주 보면 밝게 렌더링하고, 어긋날수록 어둡게 렌더링하는 것이 3D 조명 수학의 기초(Lambertian 모델)입니다.
4-2. 노멀 맵은 왜 보라색/푸른색일까? (색상과 벡터의 관계)
폴리곤의 수를 늘리지 않고 디테일을 주려면, 평평한 면 위에 그려진 각각의 픽셀마다 “가짜 법선 벡터(바라보는 방향)”를 저장해야 합니다. 우리는 이 X, Y, Z 벡터 데이터를 이미지 파일에 저장하기 위해 R, G, B 색상 채널에 각각 대응시켰습니다.
- 축의 대응:
- $X$ 축 (좌우 굴곡) = $R$ (Red)
- $Y$ 축 (상하 굴곡) = $G$ (Green)
- $Z$ 축 (앞뒤 돌출) = $B$ (Blue)
- 수학적 변환 (Remap):
- 벡터의 방향은
-1 ~ 1의 값을 가집니다. 하지만 이미지 색상(RGB)은 음수를 가질 수 없고 오직0 ~ 1(또는 0~255)의 값만 가집니다. - 따라서 벡터 데이터를 색상 데이터로 저장하기 위해 압축 공식이 사용됩니다.
- \[Color = \frac{Vector + 1}{2}\]
- 벡터의 방향은
- 보라색의 탄생 과정:
- 굴곡이 없는 완벽히 평평한 면의 법선 벡터는 정면(Z축 방향)을 바라봅니다. 즉, 벡터 값은 $(X: 0,\ Y: 0,\ Z: 1)$ 입니다.
- 이 벡터를 위의 공식에 넣어 RGB 색상으로 변환해 보겠습니다.
- $R = (0 + 1) / 2 = \mathbf{0.5}$ (빨간색 50%)
- $G = (0 + 1) / 2 = \mathbf{0.5}$ (초록색 50%)
- $B = (1 + 1) / 2 = \mathbf{1.0}$ (파란색 100%)
- 결과: RGB
(0.5, 0.5, 1.0)이 됩니다. 이 색상이 바로 미술적으로 섞였을 때 우리가 보는 노멀 맵 특유의 밝은 파란색/연보라색입니다! - 즉, 노멀 맵에서 보라색 부분은 평평한 곳이고, 붉거나 초록빛이 도는 곳은 좌우/상하로 꺾인 굴곡진 곳임을 수학적으로 증명할 수 있습니다.
게임 수학
• 삼각함수 그래프 분석
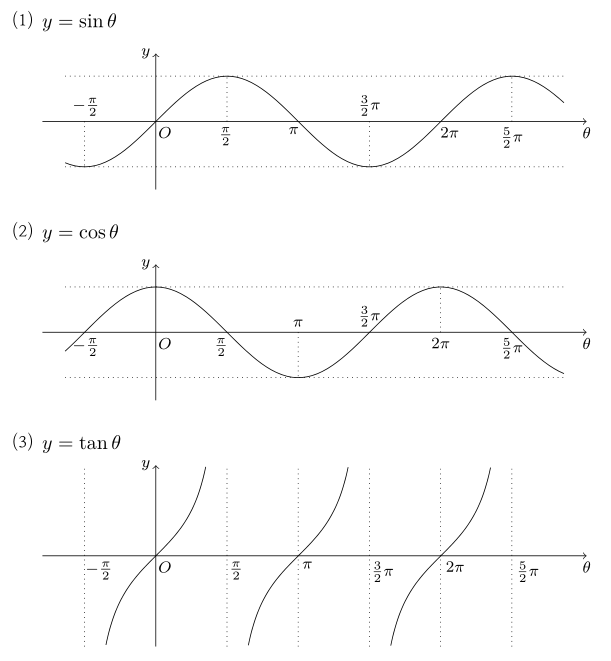
- (1) $y = \sin\theta$ (높이의 변화)
- 원에서 점이 $(1, 0)$ 즉, $0^\circ$에서 출발할 때 높이는 $0$입니다. 그래서 원점 $(0,0)$에서 시작합니다.
- $90^\circ$($\pi/2$)일 때 꼭대기($1$)에 도달하고, $180^\circ$($\pi$)에서 다시 바닥($0$)으로 내려오는 부드러운 물결(Wave) 형태입니다.
- (2) $y = \cos\theta$ (가로의 변화)
- 원에서 점이 $0^\circ$일 때, $X$좌표는 이미 제일 끝인 $1$에 가 있습니다. 그래서 $(0, 1)$에서 시작하여 아래로 내려갑니다.
- 그래프 모양 자체는 $\sin$ 그래프와 완벽히 똑같으며, 단지 왼쪽으로 $\pi/2$($90^\circ$)만큼 평행이동한 형태입니다.
- (3) $y = \tan\theta$ (기울기의 변화)
- $\tan$는 $\frac{\sin\theta}{\cos\theta}$ 즉, 원점과 점을 이은 선의 기울기를 의미합니다.
- 각도가 $90^\circ$($\pi/2$)에 가까워질수록 밑변($\cos$)은 $0$에 가까워지고 높이($\sin$)는 $1$에 가까워져 기울기가 무한대로 치솟습니다.
- 이 때문에 $\pi/2, 3\pi/2$ 위치에서 점선으로 표시된 점근선(영원히 닿지 않는 선)이 생기며, 주기는 절반인 $\pi$가 됩니다.
• 진폭과 주기
그래프의 형태를 결정하는 두 가지 핵심 요소입니다.
- 진폭: 진동의 중심축에서 최댓값(또는 최솟값)까지의 높이입니다.
- 첨부된 기본 그래프들에서 $y$축의 최댓값은 $1$, 최솟값은 $-1$이므로 진폭은 $1$입니다.
- 주기: 동일한 파동 패턴이 한 번 완전히 반복되는 데 걸리는 최소 간격(길이)입니다.
- 한 바퀴를 돌아야 제자리로 오기 때문에 $\sin$과 $\cos$의 주기는 $2\pi$ ($360^\circ$)입니다.
• 원과 삼각비, 그리고 스칼라곱의 원리
- 단위원 (반지름 $R=1$): 반지름이 $1$인 원의 중심을 $(0,0)$이라고 할 때, 원 위를 도는 특정 점의 좌표는 빗변이 $1$인 직각삼각형의 밑변과 높이와 같습니다.
- $X$ 좌표: 밑변의 길이 = $\cos\theta$
- $Y$ 좌표: 높이의 길이 = $\sin\theta$
- 즉, 원 위의 점은 무조건 $(\cos\theta, \sin\theta)$가 됩니다.
- 임의의 원 (반지름 $R$): 반지름이 $R$로 커지면 어떻게 될까요? 방향(각도)을 나타내는 단위 벡터 $(\cos\theta, \sin\theta)$에 크기(반지름 $R$)를 스칼라곱(Scalar Multiplication) 해주면 됩니다.
- 접근 공식: $R \times (\cos\theta, \sin\theta) = \mathbf{(R\cos\theta, R\sin\theta)}$
- 이 공식을 이용하면, 중심점과 각도, 그리고 거리(반지름)만으로 2차원 공간 상의 어떤 좌표(어디든) 다 접근이 가능해집니다.
• 호도법 (Radian)의 정의
그래프의 x축을 보면 $180^\circ$, $360^\circ$가 아니라 $\pi$, $2\pi$로 표기되어 있습니다. 이를 호도법이라고 합니다.
- 정의: 원의 ‘반지름의 길이’와 ‘호의 길이’가 같아질 때의 중심각을 $1$ 라디안(Radian)으로 정의하는 각도 측정 방식입니다.
- 왜 쓸까요? 각도를 $360$이라는 임의의 숫자가 아닌, ‘길이(실수)’ 기반으로 측정하여 수학적 계산(미적분 등)을 자연스럽게 만들기 위함입니다.
- 변환 공식: 원의 둘레는 $2\pi r$이므로, 한 바퀴($360^\circ$)는 $2\pi$ 라디안이 됩니다.
- $\pi = 180^\circ$
- $\pi/2 = 90^\circ$
CS
- 참고 강의: CS 강의
1. 데이터
• 정보의 기본 단위
컴퓨터의 CPU는 기본적으로 0과 1만을 이해할 수 있습니다.
- 비트 (Bit): 0 또는 1, 두 가지 정보를 표현할 수 있는 가장 작은 정보 단위. $n$비트는 $2^n$개의 정보를 표현할 수 있습니다.
- 바이트 (Byte): 8개의 비트를 묶은 단위 ($1 \text{Byte} = 8 \text{Bits}$).
- 용량 단위:
- 1 KB (킬로바이트) = 1,000 Bytes
- 1 MB (메가바이트) = 1,000 KB
- 1 GB (기가바이트) = 1,000 MB
- 1 TB (테라바이트) = 1,000 GB
(참고: 1,024개씩 묶는 단위는 KiB, MiB, GiB 등으로 별도 표기합니다.)
- 워드 (Word): CPU가 한 번에 읽어 들이고 처리할 수 있는 데이터의 크기 (CPU가 읽을 데이터의 반쪽은 하프워드, 두 배는 더블워드라고 합니다.)
- CPU는 프로그램을 워드 단위로 읽어 들이고 처리합니다.
- CPU가 한 번에 16비트를 처리할 수 있다면 1워드는 16비트입니다.
- 한 번에 32비트를 처리할 수 있으면 32비트입니다.
- 오늘날 대부분 32비트 또는 64비트를 사용합니다.
2. 컴퓨터의 숫자 표현 (정수와 실수)
• 정수의 표현 (이진법과 16진법)
컴퓨터는 정수를 2진수(0과 1)로 이해합니다.
- 이진법의 단점: 숫자가 커지면 표현해야 하는 0과 1의 길이가 너무 길어집니다. (2진수로 표현되는 수는 숫자 뒤에 아래첨자로
(2)를 붙이거나 앞에0b를 붙입니다.) - 16진법 활용: 길어지는 2진수를 짧고 가독성 있게 표현하기 위해 16진수를 많이 사용합니다. (10진수 10~15는 각각 A~F로 표현). 2진수와 16진수 간의 변환이 매우 쉬워 컴퓨터 분야(예: IPv6 주소 등)에서 널리 쓰입니다. (16진수로 표현된 수는 숫자 뒤에 아래첨자로
(16)을 붙이거나 앞에0x를 붙입니다.)
• 실수의 표현과 오차
컴퓨터로 실수를 표현할 때는 항상 오차(정밀도의 한계)가 발생할 수 있음을 기억해야 합니다. 표현하고자 하는 소수와 실제로 저장된 소수 간의 오차가 존재할 수 있다는 점입니다.
[실수 연산 오차 예시]
a=0.1,b=0.2,c=0.3일 때if a+b==c : printf("Equal") else: printf("Not Equal")를 실행하면 Not Equal이 출력됩니다. 컴퓨터 내부에는0.1 + 0.2 = 0.30000000000000004와 같이 미세한 오차가 포함된 값이 저장되어 있기 때문입니다.
1) 부동 소수점 (Floating Point)
컴퓨터는 실수를 저장할 때 소수점이 고정되지 않고 움직일 수 있는 부동 소수점 방식을 사용합니다. (필요에 따라 소수점의 위치가 이동할 수 있고, 유동적입니다.) \(\text{실수} = \text{가수}(M) \times \text{밑}^{\text{지수}(n)}\)
- 10진수 변환 (예: 123.123을 $m \times 10^n$ 꼴로 표현)
- $1.23123 \times 10^2$ -> 가수: $1.23123$, 지수: $2$
- $1231.23 \times 10^{-1}$
- 2진수 변환 (예: 10진수 107.6640625 = 2진수 1101011.1010101)
- 이 2진수를 $m \times 2^n$ 꼴로 표현하면 소수점의 위치에 따라 다양하게 표현할 수 있습니다.
- $1.1010111010101 \times 2^6$ -> 가수: $1.1010111010101$, 지수: $6$
- $110101110.10101 \times 2^{-2}$
부동 소수점에서 2의 지수가 가지는 의미
- 지수가 양수일 때: 소수점을 왼쪽으로 이동한 횟수를 의미합니다. (예: $2^6$은 왼쪽으로 6칸 이동)
- 지수가 음수일 때: 소수점을 오른쪽으로 이동한 횟수를 의미합니다. (예: $2^{-2}$는 오른쪽으로 2칸 이동)
2) IEEE 754 표준
오늘날 컴퓨터가 실수를 저장하는 가장 보편적이고 표준화된 방식입니다.
- 32비트 (단정밀도, Float): 부호
1비트 + 지수8비트 + 가수23비트 - 64비트 (배정밀도, Double): 부호
1비트 + 지수11비트 + 가수52비트64비트 방식은 지수와 가수에 훨씬 더 많은 비트를 할당하기 때문에, 32비트보다 더 넓은 범위의 숫자를 다루고 미세한 오차(정밀도 문제)를 획기적으로 줄일 수 있습니다.
3) 저장 방식
- 가수(Mantissa): 2진수 실수를 $1.\text{XXXX} \times 2^n$ 형태로 정규화(통일)한 뒤, 무조건 1로 시작하므로 앞의
1.을 제외한 나머지 소수 부분(XXXX)만 저장합니다. - 지수(Exponent): 실제 지수 값에 바이어스(Bias)라는 특별한 값을 더해서 양수 형태로 저장합니다.
- 바이어스(Bias) 구하는 공식: $2^{k-1}-1$ (여기서 $k$는 지수 표현에 할당된 비트 수입니다.)
- 32비트 (단정밀도): 지수 표현에 8비트가 사용되므로 바이어스 값은 $2^{7}-1 = \mathbf{127}$ 입니다.
- 64비트 (배정밀도): 지수 표현에 11비트가 사용되므로 바이어스 값은 $2^{10}-1 = \mathbf{1023}$ 입니다.
- 저장 예시: 앞선 예시의 $1.1010111010101 \times 2^6$이 32비트 실수로 저장될 때, 지수 부분에는 실제 지수인 $6$에 바이어스 값 $127$을 더해 $133$을 만듭니다. 그리고 이 $133$을 2진수로 변환한
10000101이 최종적으로 지수 비트에 저장됩니다.
4) 오차가 발생하는 이유
- 진법 변환의 근본적 불일치: 우리가 쓰는 10진수 소수를 컴퓨터의 2진수로 변환할 때 두 표현이 딱 맞아떨어지지 않는 경우가 많습니다.
- 예를 들어, 분수 $\frac{1}{3}$을 3진법 계열($m \times 3^n$)로 쓰면 $1 \times 3^{-1}$로 깔끔하게 떨어지지만, 10진법($m \times 10^n$)으로 쓰려면 $0.3333…$처럼 무한한 소수점이 필요한 것과 같은 이치입니다.
- 10진수 0.1의 배신: 10진수
0.1은 $1 \times 10^{-1}$로 우리에겐 매우 간단한 숫자지만, 이를 2진수($1.m \times 2^n$ 꼴)로 변환하려면 무한하게 반복되는 소수가 되어버립니다. 즉, 10진수로는 깔끔하게 떨어지는 유한소수라도 2진수로는 무한소수가 되는 값들이 존재합니다. - 한정된 저장 공간에 따른 생략: 컴퓨터의 메모리(32비트, 64비트 등)는 한정되어 있기 때문에 무한히 많은 소수점을 영원히 저장할 수는 없습니다. 따라서 2진수로 딱 맞아떨어지지 않는 소수를 저장할 때는 어쩔 수 없이 뒷부분의 일부 소수점을 생략(자르기)하여 저장하게 되며, 이 생략된 미세한 값들 때문에 연산 시 오차가 발생하게 됩니다.
3. 컴퓨터의 문자 표현 (인코딩과 디코딩)
컴퓨터가 문자를 0과 1로 이해할 수 있도록 변환하는 과정을 인코딩(Encoding)이라 하고, 반대로 0과 1을 사람이 읽을 수 있는 문자로 바꾸는 것을 디코딩(Decoding)이라고 합니다.
• 아스키 (ASCII)
- 특징: 초창기 인코딩 방식으로 알파벳, 숫자, 일부 특수 문자를 포함합니다.
- 표현 범위: 7비트를 사용하여 총 $2^7 = 128$개의 문자를 표현합니다. (나머지 1비트는 오류 검출용 패리티 비트로 사용)
- 단점: 한글을 포함해 다양한 국가의 언어를 표현할 수 없습니다.
• EUC-KR
- 특징: 아스키코드의 한계를 극복하기 위해 등장한 한글 인코딩 방식 중 하나입니다.
- 표현 범위: 하나의 한글 문자를 표현하기 위해 2 Bytes (16 Bits)를 사용합니다.
- 단점: 약 2,350자의 한글만 표현 가능하여, 지원하지 않는 일부 한글(예: ‘똠’)은 글자가 깨지는 현상이 발생합니다.
• 유니코드 (Unicode)와 UTF
- 유니코드: 한글의 모든 글자는 물론, 전 세계 대부분의 언어와 특수 문자, 이모티콘까지 모두 포함하는 통일된 다국어 문자 집합입니다. 오늘날 가장 많이 사용되는 표준입니다.
- 유니코드의 인코딩 특징:
- 기존의 아스키코드나 EUC-KR은 글자에 부여된 고유한 값을 그대로 인코딩 값으로 1:1 대응하여 사용했습니다.
- 반면, 유니코드는 글자에 부여된 값(코드 포인트) 자체를 바로 인코딩된 값으로 삼지 않고, 이 값을 다양한 방법으로 한 번 더 가공(변환)하여 인코딩합니다.
- UTF-8, UTF-16, UTF-32: 바로 위에서 말한 ‘유니코드 문자에 부여된 값을 인코딩하는 다양한 방식’들을 의미합니다. 상황에 맞게 효율적인 방식을 골라 쓰며, 뒤의 숫자는 인코딩되는 기본 비트 길이를 뜻합니다.
• Base64 인코딩
- 특징: 64진법을 사용하여 데이터를 아스키 기반의 64가지 문자(A-Z, a-z, 0-9, +, /)로 변환하는 인코딩 방식입니다.
- 용도: 텍스트뿐만 아니라 이미지 같은 이진 데이터(Binary Data)를 텍스트 형태로 이메일이나 웹에 포함해 전송할 때 매우 자주 사용됩니다.
- 변환 원리: 원본 데이터를 6비트씩 잘라서 대응하는 문자로 변환합니다. 변환 후 남는 빈자리(패딩)는
=기호로 채워지기 때문에, 인코딩된 문자열 끝에=가 보인다면 Base64일 확률이 높습니다.